

This post is a step by step example of how we can implement classical reinforcement learning to get an agent to learn how to navigate the world.
The World
BILLY THE ELF NEEDS TO REACH THE BOX OF SWEETIES BEFORE HE FREEZES TO DEATH!

In this world there are 16 possible states (squares) and 4 possible actions on each state: move up, right, down, or left.
Each state is represented by each of the squares. Some of them are empty, some of them have deadly holes and one of them has a big box of sweeties!
The goal is for little Billy to make it all the way to the big box of sweeties without falling into a hole. If he falls the game is restarted and Billy goes back to the starting point.
Frozen lake is a very cold world, so for each step Billy takes towards an empty cell he gets a negative reward of -1. This is because we want him to reach the goal in as few steps as possible before he freezes to death. When he reaches to the cell with the box of sweeties he gets a positive reward of 10.
Value Learning
The first thing is figuring out a strategy to get Billy to learn how to navigate the world to reach the box of sweeties without falling into any of the holes.
What if we get him to randomly choose actions?
Ok, so that ended in a splash. This is because on each state little Billy doesn’t have any information about what’s the best move to make. Let’s change that.
What we can do first is to randomly explore the world and keep track of which states are good, and which are bad. We can do this by assigning a value to each state based on our experience so far.
The state values represent the sum of total reward you will receive if you land in that state and then keep moving towards the highest next value until the end.
To begin with, our world will look like this.
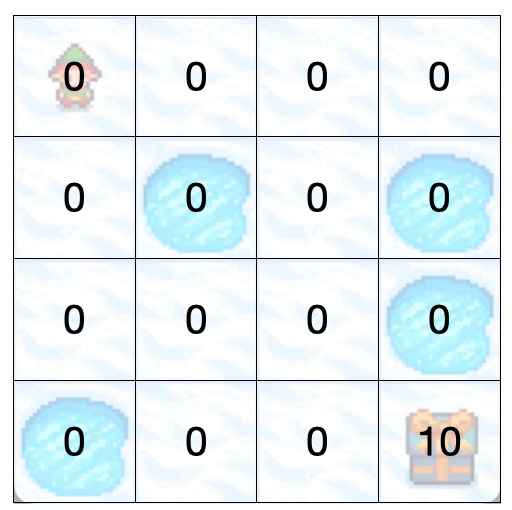
This is the world from Billy’s point of view. Billy doesn’t know anything about it so each state is assigned a value of 0. All he knows is that reaching the box of sweeties will get him a reward of 10 (and loads of sweeties).
To assign a value to a state we follow this rule:
The value of the current state is equal to the maximum value of possible next states plus the reward of moving that that state.
Or in equation terms:
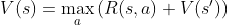
Where:
V(s)is the current value for that stateR(s,a)represents the reward of taking actionafrom our current stateswhich will land us on a next stateV(s’)V(s’)represents the value of the next statemaxrepresents picking the maximum value out of all possible current actions.
This is known as the Bellman equation and we will use it to update the values of the states.
Let’s look at an example where Billy is in a state (middle box), and he has 4 different possible actions to move to the next state. Each next state with its own value.
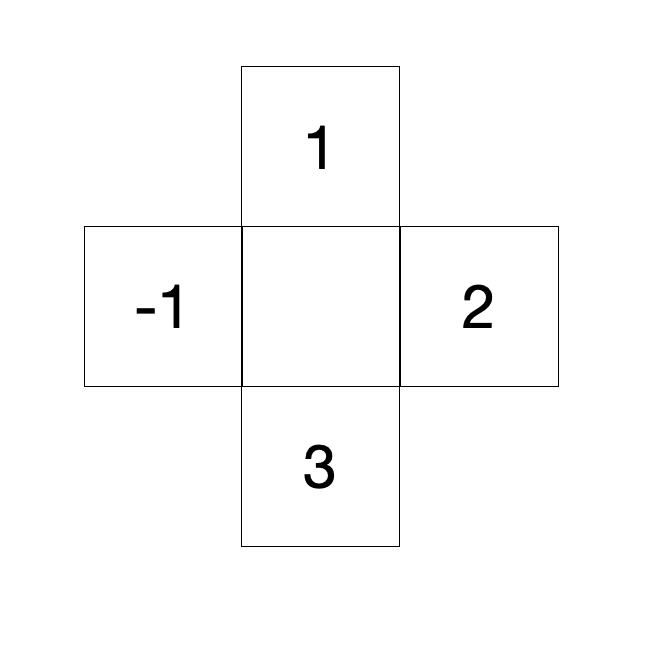
In this case the value of the current state (middle box) will be 2, which is calculated by taking the maximum value out of all 4 possible options after resolving the Bellman equation and adding the reward.
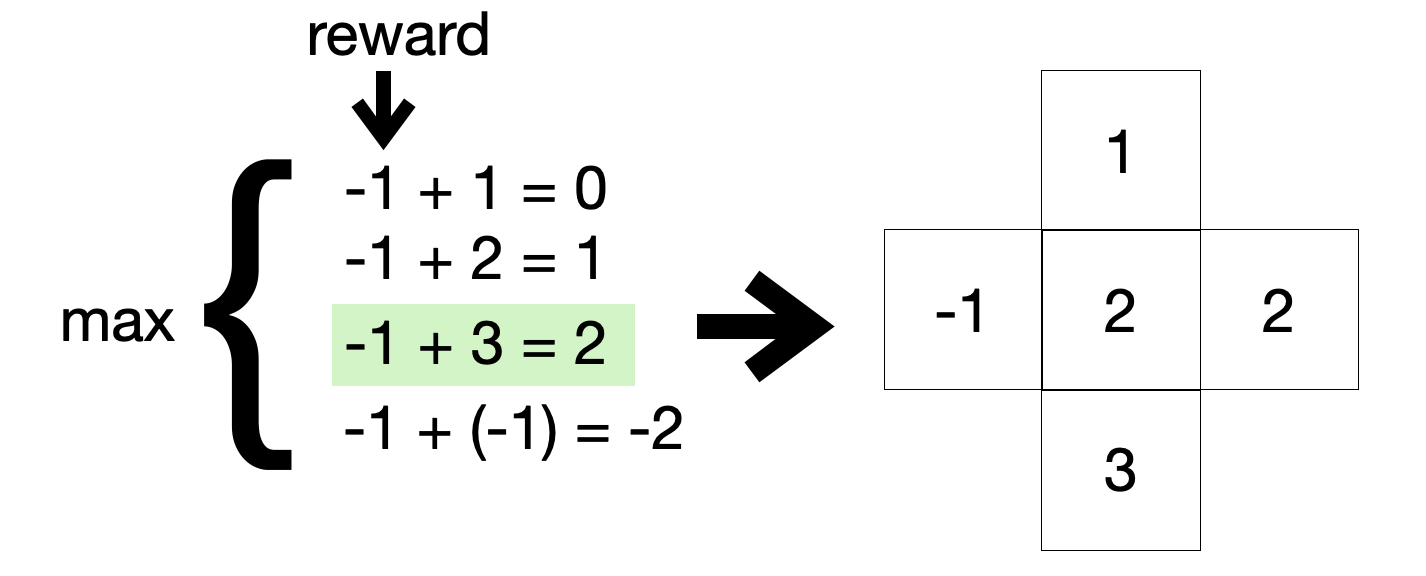
Now that we know how to update the value of each state we can roam free and learn the values of the world.
During this initial training phase we’ll be randomly picking out states in cheater mode. This means that we can jump into any random state in the world without having to follow any rules. For example, we can go from point [0,0] to point [3,2] in one move.
The idea here is to randomly iterate through all the states until we have optimal values for every state.
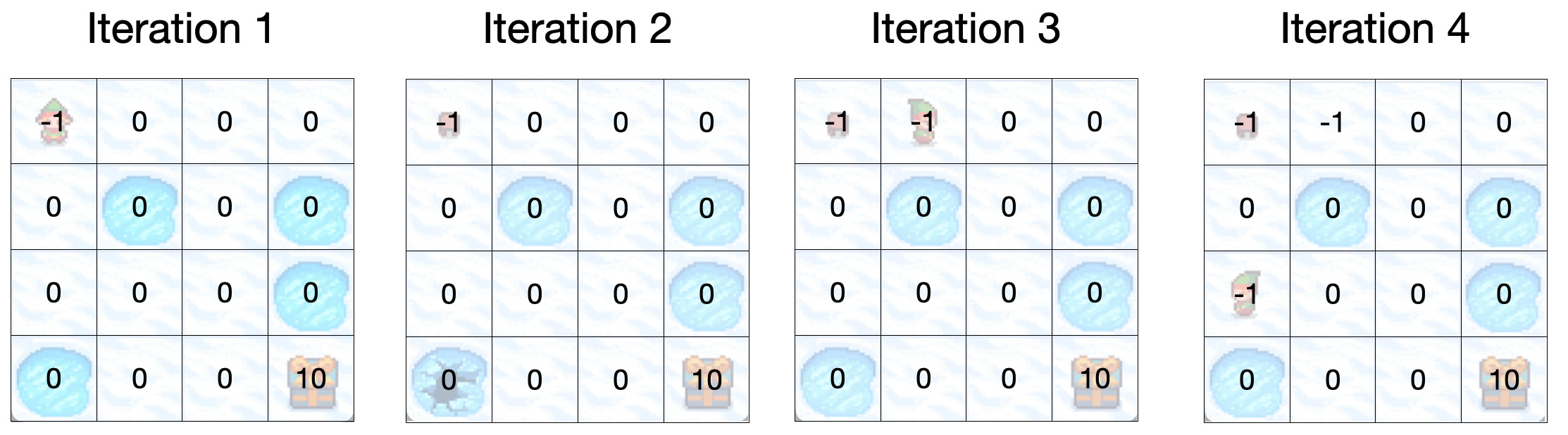
Notice how we update the value for each state Billy lands on to a new value using the equation.
For iteration 2 we don’t update the value of that state (the hole) because the game ends when we die, so there are no possible next actions to take.
At some point little Billy will reach the state right next to the box of sweeties. Once this happens the state values will start spreading in the future iterations indicating that the box of sweeties is nearby.
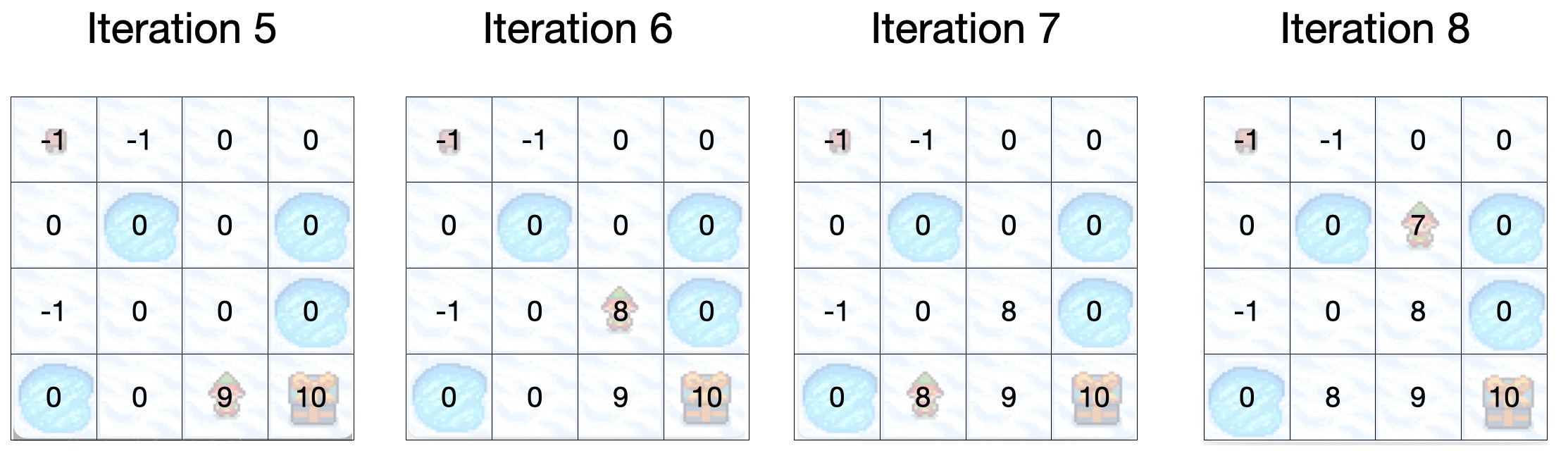
Notice how the value updates on iteration 5, and then it starts spreading across the other states in the following iterations.
We keep exploring until we have landed on each state multiple times. This will ensure that we have optimal values for each state. When we land on a state which currently has a value but the value has changed because the neighbour states have changed, we update the value. After many iterations our world will look like this:
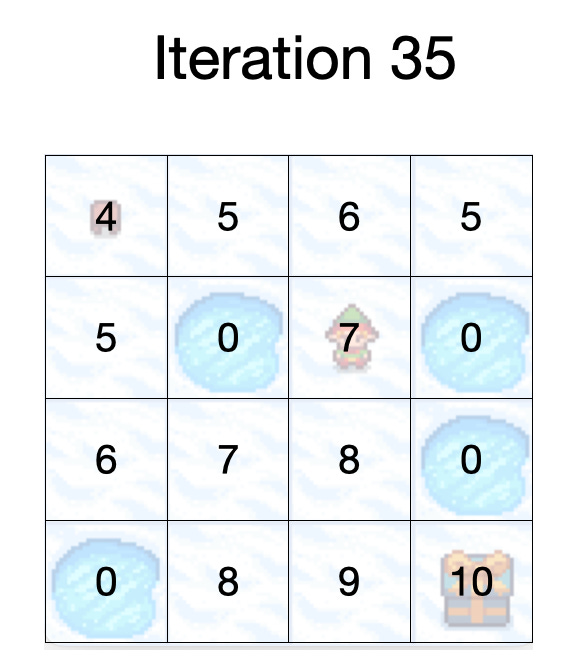
Now that we have optimal values of the world we stop the training mode and let Billy play to see if it can get to the box of sweeties. The strategy that Billy will use is that for each state he will take the action with the maximum value. If two actions are the same, Billy will pick up one at random.
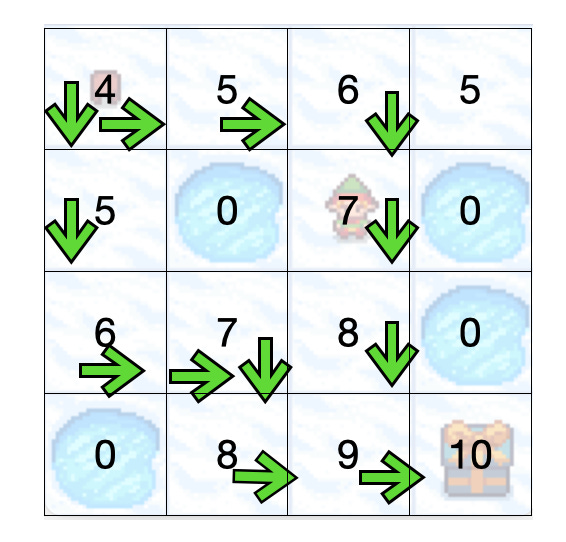
Here’s Billy Live! Let’s see if he can make it.
And Voila! Little Billy the elf now knows how to navigate the frozen lake to reach the sweeties. He’s out to have a little feast!

Update Feb 22: There was an error in the visualisations with the states values for the frozen holes being larger than any other state, which would cause Billy to want to jump in the lake every time.